Abstract
互联网上充斥着谣言帖子,谣言的传播会给社会和谐稳定带来负面影响,影响网络信息生态的健康发展。谣言的不确定性、时效性、主观性等特点,使其不同于一般的虚假网络信息。社交网络谣言检测是社交网络与信息传播研究领域的热点问题,有助于进一步提高谣言治理的效率和效果,净化网络环境。社交网络谣言被定义为在社交网络上传播且未经证实,或者已被官方确认为虚假的,而在社交网络信息中,传统的谣言检测基于特征的研究主要集中在短信、发布静态扁平特征等方面。用户、传输等方面,忽略了消息传输结构和传输群体的演化反应。国内外学者针对如何提高谣言检测效率开展了大量相关研究。从CNKI和Web of Science数据库检索中文文献138篇、英文文献331篇(检索日期:2021年8月2日),并删除无关文献和新闻报道,共计中文文献127篇、英文文献238篇。 CiteSpace 软件用于文献计量分析。通过分析相关文献的发表时间发现,谣言检测研究在2019年后迎来爆发期,国内外文献数量大幅增加。通过作者和研究机构分析发现,单个作者在国内外发表的文章最多不超过3篇。研究机构之间总体合作关系不是很密切,独立研究机构较多。通过关键词分析和现有文献回顾发现,近年来谣言检测的技术和方法主要涉及“深度学习”、“注意力机制”、“半监督学习”等技术。谣言检测的基本过程是将所选内容特征与社会情境特征有效结合,然后利用自然语言处理(NLP)、机器学习和深度学习等先进技术来预测待测信息是否虚假。随着该领域研究的深入,混合模型的检测方法越来越受欢迎。谣言检测应用主要针对“网络谣言”、“社交媒体”、“舆情监测”等问题。主要研究热点可以概括为谣言检测算法、特征和传播模型,以及不同类型谣言识别和相关任务的研究。目前的研究趋势是谣言者识别、谣言语料特征提取和多模态谣言识别。
关键词——社交网络;谣言检测;深度学习;可视化分析
I. INTRODUCTION
如今,5G通信技术和互联网移动平台的发展,使在线社交网络逐渐融入人们的生活、工作和学习。根据中国互联网络信息中心(CNNIC)2021年2月3日发布的第47次《中国互联网络发展状况统计报告》[1]:截至2020年12月,我国网民规模达9.89亿,其中手机网民9.86亿,互联网普及率达70.4%。超过50%的网民年龄在40岁以下,其中学生占21%。在这种情况下,互联网上时刻产生大量信息,质量参差不齐,充斥着各种谣言。各类社交软件的出现极大促进了谣言的快速传播,谣言可以被定义为“在私下里流传的对公共利益的事项、事件或问题的未经证实的陈述或解释。”[2],在互联网时代,谣言是“在社交网络上传播的未经证实的信息,或者是未经证实的信息。”被官方证实为虚假信息,并在社交网络中传播”。[3,4]。社交网络中谣言泛滥的现象,使人们很难在纷繁复杂、质量参差不齐的信息中找到自己需要的可用信息,降低了人们获取信息的质量,甚至严重影响了正常的社会秩序。例如,2020年初爆发的COVID-19在互联网上引起了广泛关注和讨论。而一些谣言引起了团体的负面情绪。
谣言可以被定义为“在私下里流传的对公共利益的事项、事件或问题的未经证实的陈述或解释。”[2],在互联网时代,谣言是“在社交网络上传播的未经证实的信息,或者是未经证实的信息。”被官方证实为虚假信息,并在社交网络中传播”。[3,4]。社交网络中谣言泛滥的现象,使人们很难在纷繁复杂、质量参差不齐的信息中找到自己需要的可用信息,降低了人们获取信息的质量,甚至严重影响了正常的社会秩序。例如,2020年初爆发的COVID-19在互联网上引起了广泛关注和讨论。而一些谣言引起了团体的负面情绪,造成许多不良后果,影响社会和谐稳定。
因此,如何快速有效地甄别谣言,逐渐受到人们的重视。谣言检测、舆情监测与管理等相关话题[5-7]近年来引起了学者的广泛关注。本文利用CiteSpace软件对国内外谣言检测的相关研究进行分析,总结该领域的研究热点和趋势,希望为后续研究提供参考和帮助,从而更好地控制谣言、净化谣言。网络环境。
II. DATA SOURCES AND RESEARCH METHODS
A. Data sources and processing
选取CNKI期刊数据库和Web of Science为数据源,CNKI中中文文献选取采用“(主题=谣言检测)OR(主题=谣言识别)OR(主题=假新闻检测)OR(主题=假新闻)”新闻检测)”作为检索模式。在Web of Science中输入“谣言检测(主题)或谣言验证(主题)或假新闻检测(主题)”,搜索时间不限。共检索到中文文献138篇、英文文献331篇(检索日期为2021年8月2日)。剔除无关文献和新闻报道,共找到中文文献127篇,英文文献238篇。
B. Research method
CiteSpace[8]是陈超梅教授团队开发的知识图谱分析工具,旨在通过可视化方法直观地呈现科学知识的结构、规则和分布。本文基于CiteSpace对选取的文献进行计量分析,绘制知识图谱,分析谣言检测领域文献的主要作者、机构和关键词,总结该领域的研究热点,探索研究方向。
III. PUBLISHING YEAR DISTRIBUTION
从图1可以看出,国内外发表的谣言检测研究趋势较为相似,可分为三个阶段。 2011年至2015年作为研究的起步阶段,国内外关于谣言检测的研究较少,仅发表了少量零星文献。 2016年至2018年,国内外文献数量增长缓慢。
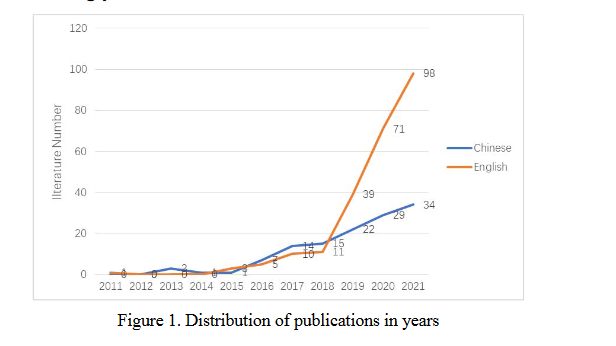
这一阶段,国内文献的增长速度略快于国外文献,这可能与国内对信息管控的要求更加严格有关。 2019年以来,谣言检测研究迎来爆发期,国内外文献数量大幅增加。 2021年半年,国外发表论文数量已超过2020年全年。尤其是国外研究增长速度极快,从2018年国内外发表论文数量,到超过是近两年国内研究数量的两倍。例如,互联网和移动平台的普及提供了背景条件,机器学习技术的发展提供了技术条件。
这些都充分表明谣言检测是当前的热门研究课题之一,并且可以相信在接下来的几年里它将继续保持一定的热度。
IV. DISTRIBUTION OF AUTHORS AND INSTITUTIONS
A. Author distribution
CiteSpace的作者映射可以清晰地反映作者之间的合作情况,也可以揭示作者的发表状态。节点的连接表明作者之间存在合作关系。节点越大,出版物就越多。图2、图3分别展示了中外作者的合作关系。

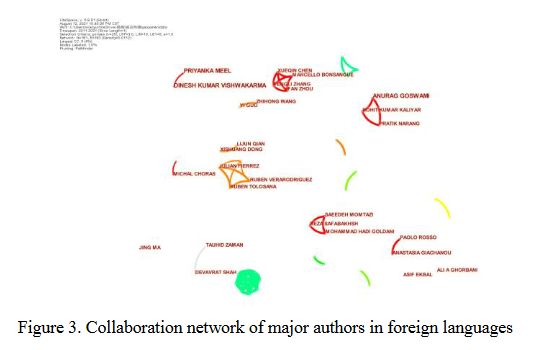
从图中可以看出,国内谣言检测文章的作者主要包括但志平、尹鹏博和刘侃等,国内主要团队包括来自新疆师范大学的尹鹏博和彭程。祖昆林,赵明伟,郭凯等,大连理工大学;但志平、李敖、中国三峡大学其他;梁刚,杨进等,四川大学。外文作者主要包括Anurag Goswami、Priyanka Meel、Dinesh Kumar Vishwakarma等,主要团队包括Bennett大学的Anurag Goswami、PRATIK等人。陈学勤,马塞洛,周,范等。中国理工大学;马德里自治大学的 Ruben Tolosana、JULIAN FIERREZ 等人。
对比图2和图3,可以发现两张图都比较分散,作者节点之间只有少数连接,其他作者有孤立的节点或者只有少量连线,作者连线的节点大多是同一机构和组织,说明本研究作者之间的合作较少,大部分作者为独立研究,没有形成稳定的合作关系。图2中的网络密度为0.0097,图3中的网络密度为0.0112,表明国外作者之间的合作比国内作者之间的合作更紧密。此外,国内外单个作者发表的文章最多不超过3篇,缺乏深入的研究,可能是因为谣言检测的整体研究进展尚未处于成熟阶段。
B. Organization distribution
从图4可以看出,中国科学院大学、三峡大学、四川大学和中南财经政法大学节点较大,在谣言检测方面的研究较多。以中科院大学为牵头,形成了包括中科院研究所、石河子大学、华北计算机系统研究所等在内的大型合作网络,四川大学、华东成都信息工程大学师范大学和上海工程技术大学也有一定的合作关系,而其他院校联系不紧密,只在院校内部进行研究,缺乏合作意识。
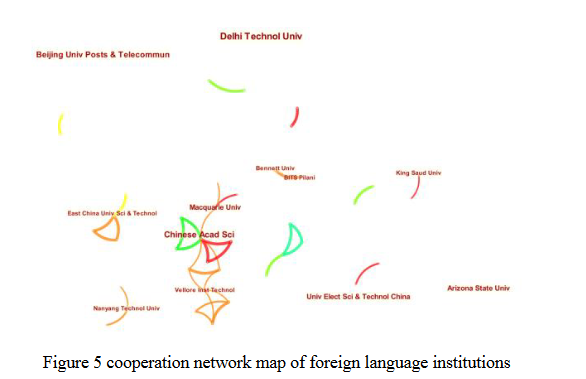
图5显示,主要外语研究机构包括德里理工大学、亚利桑那州立大学、麦考瑞大学等。以中国科学院、华东理工大学、华威大学等为牵头,已形成多个合作团体,存在一定程度的跨国合作。多个机构之间的合作比中国文学机构的合作更强。但整体合作关系还不是很密切,独立研究机构较多。
V. RESEARCH TOPIC ANALYSIS
A. Keywords co-occurrence analysis
本文选择绘制关键词共现图和关键词聚类图来分析谣言检测领域的热点和研究方向。
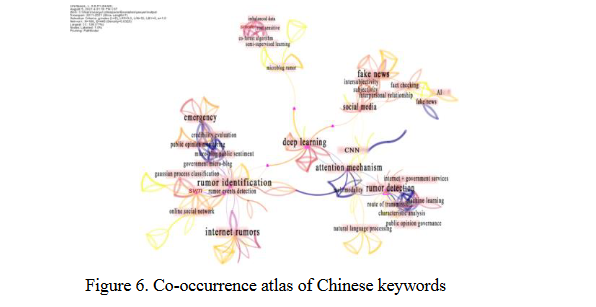
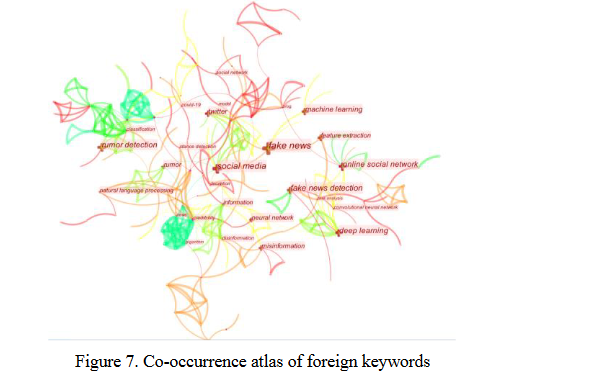 图6和图7分别是中外文献中绘制的关键词共现图。
图6和图7分别是中外文献中绘制的关键词共现图。
两个关键字之间的一条线表示文档包含在同一个文档中。通过关键词分析,可以把握文章整体的研究主题。关键词共现图中的节点越大,表明该关键词的关注度越高,相关研究越多,对整个网络的引导作用越强。根据图6可知,除了“谣言检测”、“谣言识别”关键词外,最大的节点还有“深度学习”、“注意力机制”、“半监督学习”等,这些是谣言检测技术和方法,除了“网络谣言”、“社交媒体”、“舆情监测”等节点较大之外,也代表了谣言检测的不同应用方向。中介中心性衡量节点作为中介者的能力。中介中心性高的节点起着重要的桥梁作用,图中紫色节点,如“Twitter”、“深度学习”、“社交媒体”等关键词。
从图7可以看出,外语更偏向于假新闻的研究,其他大节点如“深度学习”、“社交网络”、“机器学习”等与中外语的研究基本一致。中国文学。图中中介中心度高的节点有“可信度”、“数据挖掘”等,通过对比两图的差异可以看出,图7中的节点数和线路数较多,说明国外研究方向更加广泛,研究数量较多也是有原因的。
B. Research Hotspot Analysis
根据CiteSpace中的关键词进行聚类。采用LLR算法提取聚类标签,绘制关键词聚类图,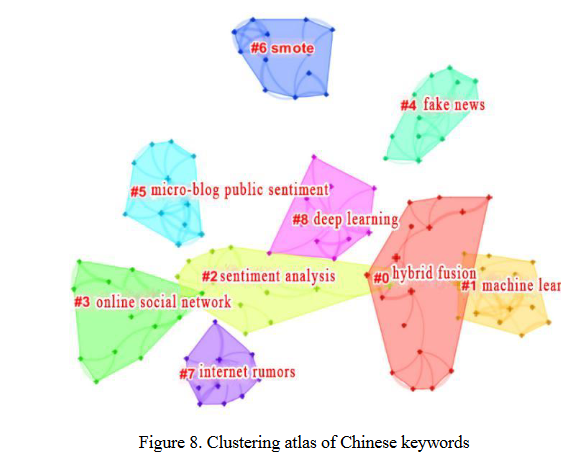 如图8和图9所示。
如图8和图9所示。
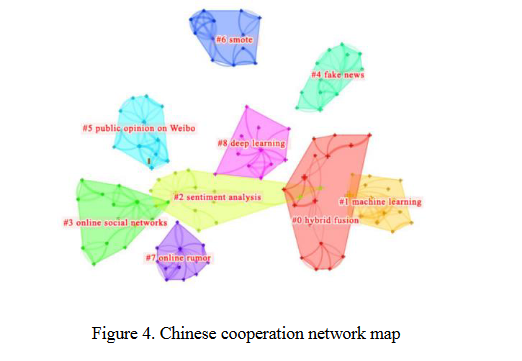
 可以看出,中文文献主要形成10个聚类,包括“混合融合”、“机器学习”、“情感分析”国外文献中形成了八种聚类结果,分别是“任务分析”、“姿态检测”、“卷积神经网络”和“错误信息”。
可以看出,中文文献主要形成10个聚类,包括“混合融合”、“机器学习”、“情感分析”国外文献中形成了八种聚类结果,分别是“任务分析”、“姿态检测”、“卷积神经网络”和“错误信息”。
(1) Rumor detection algorithm research
谣言检测问题通常被定义为二分问题,因此大部分研究都是监督学习中的分类算法。早期,传统的机器学习方法主要用于自动检测谣言。首先,选择有效表示数据的特征进行提取,并构建和训练适当的分类器。最后,对未经训练的数据进行测试和评估,以确定数据内容是否为谣言。常用的是SVM和决策树。 Castillo提取了Twitter帖子的特征,并分别通过决策树、支持向量机、决策规则和贝叶斯网络进行分类。结果表明,决策树的分类效果最好[9]。 Wu选择支持向量机、随机森林,并构建集成学习分类算法[10
与传统机器学习相比,深度学习降低了特征工程的要求,可以学习更复杂的规则,分类效果更好。它逐渐成为谣言检测算法的主要研究对象。马等人。首次使用深度学习模型研究微博谣言检测,并采用双层GRU网络完成谣言事件的特征表示和分类任务。与依赖手动特征的机器学习算法相比,深度学习模型的准确性显着提高[11]。考虑到谣言检测和情绪分析之间的相似性,沉瑞林等人。将情绪识别作为谣言检测的辅助任务。采用深度学习的多任务学习框架,通过两个任务的联合训练来提高模型的学习能力[12]。
除了监督学习之外,有学者认为目前谣言数据集的标签太少。如果全部人工标注耗时费力,则采用半监督学习算法进行谣言检测任务。例如,陈庚比较了不同检测学习和半监督学习算法的效果,发现ImCo-Forest算法在标记比例较小时效果最好[13]。通过少量的标记样本来改进道路,并通过使用少量的标记样本来提高少数类别的分类精度[14]。
(2) Research on rumor characteristics
谣言特征的研究和谣言检测算法的研究相辅相成,提取合适的特征来提高检测的准确性,是谣言检测的重要组成部分。有以下几种谣言:
a) 内容特征。内容特征包括显性文本特征、隐性文本特征、多媒体特征等。显式文本特征主要包括文本长度、@、#、和!如符号数量、是否有链接、包含表情符号等。隐含文本特征主要是神经网络从文本中提取的深层语义特征和情感特征。现有的许多谣言以多种形式出现,多媒体特征与文字特征部分相辅相成。
b) 用户特征。用户特征一般是指发布谣言或参与谣言传播过程的用户的特征。谣言用户与非谣言用户之间存在明显差异[15]。常见的用户特征也可以是显式的或隐式的。显性的用户特征包括性别、年龄、职业等基本信息。隐式用户特征是指无法直接获取的用户特征,如用户历史情感倾向、用户可信度、用户声誉等,需要通过其他方式计算或提取。
c) 传播特性。传播特征是谣言在网络传播中的一些特征,包括转发数、点赞数、评论数、每次转发和评论的时间间隔、谣言发生和传播的地理位置等。
在共同特征的基础上,学者们通过进一步的研究,提出了许多其他隐含的谣言特征。例如,吴等人。构建了微博谣言检测的特殊特征集,并提出了用户可信度、情感一致性和区域相关性三个新特征[9,10]。毛二松等.提出了几个新的测试特征,即评论数与转发数的差异、意见领袖的传播影响力和用户的历史信用度[16]。根据谣言传播公式,王志宏提出事件流行性、模糊性和传播性三个特征[17]。除了谣言特征提取之外,特征选择也非常重要。剔除不重要的特征可以在一定程度上提高检测效率并减少对结果的干扰
(3) Research on rumor propagation model
谣言传播模型的研究主要借鉴传染病的传播模型,通过传播动力学构建网络拓扑图,挖掘谣言传播模式,通过研究传播过程中的异常节点、溯源谣言来识别谣言。通过传播模型,我们还可以预测谣言的发展趋势,研究抑制谣言、消除谣言的对策[18,19]。经典的谣言传播模型包括SIR模型和SEIR模型[20],SIR模型将网络节点分为三类:易感者、感染者和移除者。 SEIR模型将节点分为健康节点、潜伏节点、传播节点和免疫节点。一些学者还改进了经典的谣言传播模型或构建了新的网络结构来识别谣言。例如,Jin提出了一种分层传播模型,即由事件、子事件和消息三层组成的可信度网络,并使用图形优化框架来推断事件的可信度[21]。'
(4) Research on different types of rumor detection
随着互联网的发展,常见的谣言检测逐渐成为社交媒体中的谣言检测,即社交网络谣言检测,由于社交媒体的复杂性,不同谣言对象检测的研究也多种多样。首先,有单文本和多文本粒度的谣言检测[3],单文本谣言检测是指对单个消息的检测对象识别是否为谣言。单一文本谣言特征相对简单且易于提取,因此检测效果不佳。多文本谣言检测也是事件级谣言检测,指的是谣言传播过程中的一系列帖子,如转发、评论等。事件级谣言检测功能更多,检测准确率更高,但也容易受到事件后采集完整性的影响。其次,纯文本谣言检测和多模式谣言检测。目前,社交媒体上的帖子并不局限于文字形式,很多帖子都包含图片、视频等格式的内容。纯文本谣言检测仅检测帖子中的文本内容,而多模式谣言检测则同时提取文本特征和多媒体特征来检测这两个特征。最后,是对不同类型谣言的识别。常见的谣言类型可分为政治类型、社会新闻类型、生活常识类型、财经经济类型等。不同类型的谣言在发布动机和传播动机上有一定的差异,因此谣言的特征也有差异,需要单独研究。
(5) Relevant task research
相关任务是与谣言检测相关的研究点,但不完全属于谣言检测的范围。这些任务可以辅助谣言检测并提高检测的准确性。它可以分为以下任务:
a) 情绪分析。情感分析是指通过计算技术对文本的主观和客观进行挖掘和分析,并对情感倾向进行分类和判断[22]。与非谣言内容相比,谣言伴随着更强的负面情绪和更明显的情绪倾向[23],其他用户更容易经历负面情绪,如愤怒、担忧、恐慌等。因此,谣言作为密切相关的任务检测、情感分析对于准确识别谣言有很大帮助。
b) 位置检测。据观察,谣言帖子经常会导致用户发表各种最具争议性的评论[24]。立场检测是判断用户对帖子描述的内容是支持、中立还是反对,并利用用户的观点来辅助判断帖子是否为谣言。位置检测本质上是一个排序任务。
c) 网络水军及风险账户检测。现在社交媒体上存在大量恶意账号专门传播虚假信息,这些账号是真正的水军,拥有大量的社交机器人,例如,研究表明,2016年大选前一周,大约有1900万个机器人在推特账号上支持特朗普,严重影响了美国总统大选的在线讨论。现有方法主要从用户活动和社交网络信息中提取特征[25],为了识别有风险的社交媒体账户,这些风险账户可以作为谣言传播检测的焦点,并与正常用户特征区分开来。
d) 虚假图像和音频检测。深度学习使得识别伪造图像和音频的方法变得越来越容易和困难。有些谣言通过假图片视频等手段进行迷惑,有必要检查社交媒体中图片和音频的可信度和真实性,对于虚假图片、音频,研究和测试就变得很重要,因为Tolosana Deepfakes检查对谣言测试的改进措施,并详细说明了现有的挑战[26]。
C. Abrupt analysis

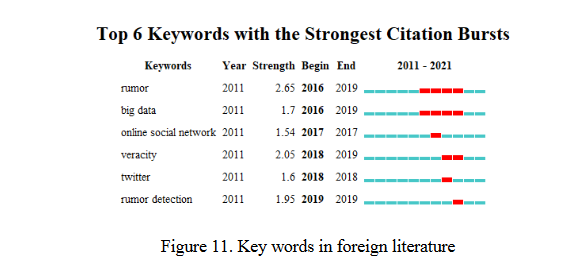
图10和图11是中外文关键词出现图。涌现词是在一定时间内出现频率突然增加的关键词,涌现图反映了不同时间段的研究趋势。对比两个数字可以看出,2016年至2019年国外的爆发词大多是Rumor,而之前的研究大多与假新闻有关。事实上,虚假新闻也是谣言检测的一种,说明国外的研究范围已经扩大。在中国,2016年至2017年的爆发词是网络谣言,而2018年的爆发词是假新闻和谣言传播,这表明中国的研究对象是一个从粗到细的过程。
对于社交媒体谣言的研究,国内出现时间为2018年,国外出现时间为2017年,早于国内。这可能是因为Twitter和Facebook的流行早于微博。到 2016 年,62% 的美国成年人在社交媒体上阅读过新闻。近两年中文涌现词有注意力机制、多模态和自然语言处理,这表明国内研究更倾向于多模态谣言检测和神经网络谣言检测。谣言检测和真实性是外语中的常用词,这表明国外的研究更多的是谣言检测方法和事实核查。
VI. CONCLUSION AND FUTURE WORKS
A. Research trends
谣言检测是一个研究热点问题,其研究趋势随着环境的变化和研究的深入而不断变化。本文梳理了以下主要研究趋势:
(1) Dynamic modeling and recognition of the portrait of the rumor subject
谣言主体一般是指发布、传播谣言的用户。谣言主体通常具有较多的相似特征,大多数谣言博主都拥有多个谣言。因此,对于谣言检测任务,用户特征可以作为提高检测准确率的重要特征之一,已被许多学者所采用[23]。用户画像是通过数据分析用户的重要方式。它通过分析用户的各种行为数据,提取代表用户的综合虚拟网络图像[27]。建立谣言主体动态用户画像,对于发现网络水军、及时发现异常用户有很大帮助,从而在谣言传播的早期起到预防作用。
(2) Feature extraction of rumor corpus
近年来,随着深度学习研究的逐步深入,Google团队提出了Transform和BERT模型,在自然语言处理领域取得了重大突破。借助深度学习技术,谣言语料的特征提取方法逐渐多样化,特征层次不断加深。如何提取更有效、更丰富的谣言特征一直是学者们研究的重点,比如通过BERT获得谣言文本的语义建模[28],通过RNN[11]获得谣言随时间变化的特征,事件、和子事件[29]以及传播模型辅助信息提取等其他手段。
(3) Multi-mode rumor detection
目前,多媒体内容已逐渐成为网络信息的主流,而在谣言传播过程中,包含图片和音频的信息比单一文本信息更容易引起关注,其来源和真实性更难以验证,因此多模式谣言检测是当前的一个主要研究趋势。多模态谣言识别有两个关键。一是从图像、音频等多媒体信息中提取谣言特征。包含明亮颜色或模糊图像的图像是虚假信息的标志。多媒体特征提取有传统的方法,例如从音频中提取基频、能量和MFCC。还有神经网络方法直接提取图像音频特征,或者提取图像音频中包含的文本信息[30]。二、多模态特征融合技术。需要准确捕捉各个模式之间的关系,更好地对单模式独立特征和多模式交互特征进行建模。合适的融合方法有助于提高检测的准确性,而不合适的融合方法会干扰网络判断。多模态数据的融合可以为模型决策提供更多信息,提高整体决策结果的准确性[18]。
B. Research conclusions
本文利用CiteSpace软件对CNKI和Web of Science中的谣言检测文章进行了深入分析。从文献发表年份的分布来看,谣言检测是当前的热门话题,并将在未来几年保持一定的热度。通过关键词共现和聚类分析,研究热点可归纳为五个主要方向:(1)谣言检测算法研究。 (2)谣言检测相关特性研究。 (3)谣言传播模型研究。 (四)各类谣言识别的相关研究。 (五)谣言检测相关任务研究。谣言检测仍在快速发展。希望本文的研究能够为后续研究提供参考和帮助,推动谣言检测方法的进步,净化网络环境。